1前言
本篇博客主要记录的是使用Tensorflow搭建Seq2Seq模型,主要包括3个部分的叙述:第一,Seq2Seq模型的训练过程及原理。第二,复现基于SouGouS新闻语料库的文本摘要的应用。第三,Seq2Seq模型中存在的问题及相应的Trick。
本篇博客参考多篇博客完成,主要是作为自己的学习笔记使用,但最终还是掺杂自己的理解和自己的亲身实现过程。后面会给出参考博客的链接。
2浅谈Seq2Seq
2.1Seq2Seq概要
一般来说,Seq2Seq模型主要是用来解决将一个序列X转化为另一个序列Y的一类问题,此处有点类似于隐马尔科夫模型,通过一系列随机变量X,去预测另外一系列随机变量Y。但是不同的是,隐马尔科夫模型中的随机序列与随机变量系列一一对应而Seq2Seq模型则并不是指一一对应的关系。Seq2Seq模型主要的应用包括机器翻译,自动摘要等一些端到端的生成应用。
目前来说,对于Seq2Seq生成模型来说,主要的思路是将该问题作为条件语言模型,在已知输入序列和前序生成序列的条件下,最大化下一目标词的概率,而最终希望得到的是整个输出序列的生成出现的概率最大:
说明:1.其中T表示输出序列的时间序列大小,y1:t-1表示输出序列的前t-1个时间点对应的输出,X为输入序列。通常情况下,训练模型的时候y1:t-1使用的是ground truth tokens,然而在测试过程中,ground truth tokens便不可知,需要使用前期预测到的y‘1:t-1来表示,这将会引发问题7 Exposure Bias,相应的解决的trick会在第4部分提出。
2.在预测输出序列的每个token时,采用的都是最大化下一目标词(token)的概率,来得到token,对于整个句子或者说序列来说,这种解法是贪心策略,带来的是局部最佳。对于一个端到端的生成应用来说,将会追求整个序列的最佳,换句话说,希望最后的生成序列的tokens顺序排列的联合概率最大,找到一个全局最优。

2.2Seq2Seq模型推导
Seq2Seq模型是基于输入序列,预测未知输出序列的模型。它有两个部分组成,对输入序列的Encoder编码阶段和生成输出序列的Decoder解码阶段。定义输入序列[x1,x2,…,xm],由m个固定长度为d的向量构成;输出序列为[y1,y2,…,yn],由n个固定长度为d的向量构成;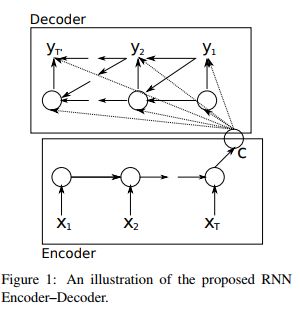
上图中可以看出,Encoder使用RNN编码后形成语义向量C.再将C作为输出序列模型Decoder的输入。解码过程中每一个时间点t的输入是上一个时刻隐层状态ht-1和中间语义向量C和上一个时刻的预测输出yt-1.之后将每个时刻的yt相乘得到整个序列出现的概率。其中f是非线性的激活函数。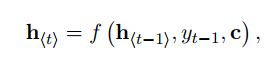
最后Seq2Seq两个部分(Encoder和Decoder)联合训练的目标函数是最大化条件似然函数。其中θ为模型的参数,N为训练集的样本个数。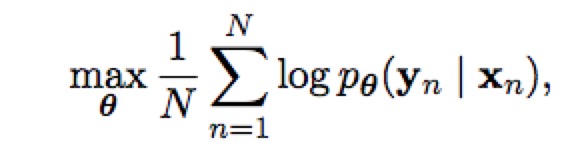
下图为网上某篇博客上的图,展示的是一个机器翻译的多层Seq2Seq的模型。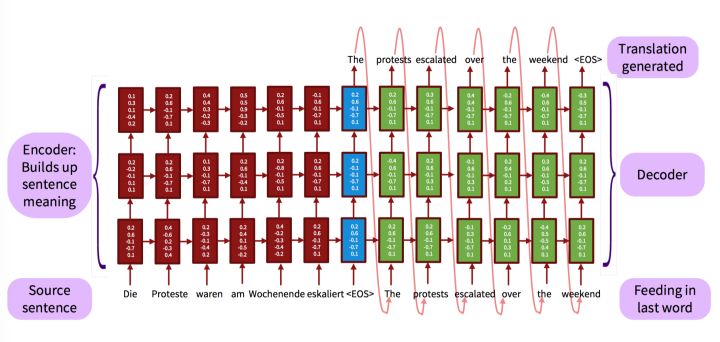
2.3Seq2Seq模型上的Attention注意力机制
尽管Seq2Seq中的Encoder可以将RNN替换成LSTM来增强最终语义向量C对长的输入序列的信息表上,但是由于传统的Seq2Seq模型对输入序列进行编码输出的语义向量C是固定的,一个向量并不能很好的编码出输入序列所有包含的信息,而解码阶段则受限于该固定长度的向量表示。因此,此篇论文中Neural Machine Translation by Jointly Learning to Align and Translate引入Attention机制。
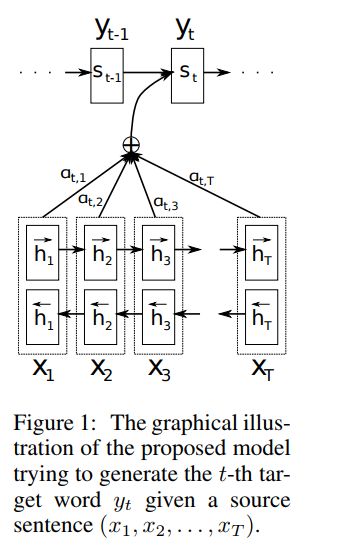
论文中提出,将Encoder中的每一个时刻的隐藏状态都保存至一个列表中[h1,h2,…,hm],在Decoder解码每一个时刻i的输出时,都需要计算Encoder的每个时刻的隐藏状态hi与Decoder的输出时刻的前一个时刻的关系si-1的关系,进而得到Encoder的每个时刻的隐藏状态对Decoder该时刻的影响程度。如此,Decoder的每个时刻的输出都将获得不同的Encoder的序列隐藏状态对它的影响,从而得到不同的语义向量Ci。
如上图,Decoder阶段的每个时刻的隐藏状态si,都会根据由Encoder阶段的隐藏状态序列对Decoder阶段上一个时刻(i-1)的隐藏状态的影响也就是我们的语义向量Ci和上一时刻的的状态si-1,上一个时刻的输出yi-1三者通过一个非线性函数得出。
其中,Ci是根据Encoder编码阶段的各个隐藏状态(向量)的权重和。
其中,每个时刻的权重aij表示Encoder编码阶段的第j个隐藏状态对Decoder解码阶段的第i个隐藏状态的权重影响。
其中,eij为Encoder编码阶段的第j个隐藏状态和Decoder解码阶段的第i-1个隐藏状态的联合前馈网络关系。
整个计算Ci的过程为:分别计算Encoder编码阶段的每个隐藏状态和Decoder解码阶段的第i-1个隐藏状态前馈关系,再进行Softmax归一化处理计算出该Encoder编码阶段的隐藏状态的权重aij,最后将所有的Encoder编码阶段的隐藏状态的进行权重加和。
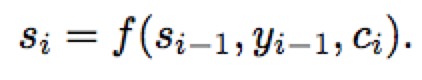
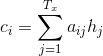

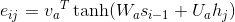
3基于Seq2Seq模型的文本摘要应用复现
本次实践主要是采用SouGouS新闻语料库,基于Seq2Seq模型进行的文本摘要的代码实现,尽管网上已经有大神已经实现了的,但是自己能跟着大神的代码走一遍,理解一遍,将会比只看不动手来的强。因为其中涉及到很多细节性的编码问题和细节性的模型处理问题。主要参考rockingdingo大神的实现。python版本为2.7.X.
3.1SouGouS新闻语料库处理
数据集下载地址选择的是精简版下载。
step1 提取出新闻内容和标题cat ./news_sohusite_xml.dat | iconv -f gbk -t utf-8 -c | grep "<content>" > corpus.txtcat ./news_sohusite_xml.dat | iconv -f gbk -t utf-8 -c | grep "<contenttitle>" > corpus_title.txt
step2 选出了10万行数据样本head -10000 corpus.txt >corpus_10000.txthead -10000 corpus_title.txt >corpus_title_10000.txt
step3 数据预处理
主要的工作为:文本的清洗工作,特征字符的删除,日期替换,数字替换。词汇表的建立,语句的分词工作,将语句的分词替换成词汇表的词的id组成。data_util.py.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 文本的预处理工作
# step1 获取出文本内容
data_content,data_title = get_title_content(content_fp,title_fp)
ndexs = np.arange(len(data_content))
# step2 文本清洗工作
for index,content,title in zip(indexs,data_content,data_title):
data_content[index] = remove_tag(content).encode('utf-8')
data_title[index] = remove_tag(title).encode('utf-8')
# step3 划分数据,训练集,验证集,测试集
get_train_dev_sets(data_content,data_title,train_rate=0.7,dev_rate=0.1,
tr_con_path=src_train_path,tr_title_path=dest_train_path,
dev_con_path=src_dev_path,dev_title_path=dest_dev_path,
test_con_path=src_test_path,test_title_path=dest_test_path
)
# step4 将各个样本的语句进行切分,并将各个语句中的词转换成词汇表中该词对应的id.
prepare_headline_data(root_path,vocabulary_size=80000,tokenizer=jieba_tokenizer)
3.2Seq2Seq+Attention模型搭建
Tensorfolw Github提供了一个基于Seq2Seq模型实现的textSum可参考其做一定程度的修改。构建模型的文件是seq2seq_model.py.
step1 Encoder+Decoder+attention层的构建
tensorflow中提供了5个构造seq2seq函数,这里使用的是embedding_attention_seq2seq主要介绍内部详细实现。文件为seq2seq_attn.py
basic_rnn_seq2seq:最简单版本,输入和输出都是embedding的形式;最后一步的state vector作为decoder的initial state;encoder和decoder用相同的RNN cell, 但不共享权值参数;
tied_rnn_seq2seq:同1,但是encoder和decoder共享权值参数
embedding_rnn_seq2seq:同1,但输入和输出改为id的形式,函数会在内部创建分别用于encoder和decoder的embedding matrix
embedding_tied_rnn_seq2seq:同2,但输入和输出改为id形式,函数会在内部创建分别用于encoder和decoder的embedding matrix
embedding_attention_seq2seq:同3,但多了attention机制.
1 | # 1.Encoder编码器的构造,size为隐藏层单元数,num_layers为LSTM的层数 |
step2 seq2seq的损失函数1
2
3
4
5
6
7
8
9
10
11
12
13# 真实的labels,此处采用的loss函数为sampled_softmax_loss,后面会讲述到为什么是这个loss
labels = tf.reshape(labels, [-1, 1])
local_w_t = tf.cast(w_t, tf.float32)
local_b = tf.cast(b, tf.float32)
local_inputs = tf.cast(inputs, tf.float32)
loss_op = tf.cast(tf.nn.sampled_softmax_loss(
weights=local_w_t,
biases=local_b,
labels=labels,
inputs=local_inputs,
num_sampled=num_samples,
num_classes=self.target_vocab_size),
tf.float32)
step3 梯度计算和优化1
2
3
4
5
6
7
8
9
10
11
12# Gradients and SGD update operation for training the model.
# 1.获取出tf session中trainable=True的参数变量。
params = tf.trainable_variables()
# 2.设置参数更新优化器
opt = tf.train.GradientDescentOptimizer(self.learning_rate)
# 3.求参数的梯度值,其中self.losses[b]为目标值(代价函数的表达式)
gradients = tf.gradients(self.losses[b], params)
# 4.梯度修剪,修正梯度值,用于控制梯度爆炸的问题。梯度爆炸和梯度弥散的原因一样,
#都是因为链式法则求导的关系,导致梯度的指数级衰减。为了避免梯度爆炸,需要对梯度进行修剪。
clipped_gradients, norm = tf.clip_by_global_norm(gradients,max_gradient_norm)
# 5.求取更新参数的tensorflow的节点
self.updates.append(opt.apply_gradients(zip(clipped_gradients, params), global_step=self.global_step))
step4 模型训练1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 4.1 根据随机选取的bucket_id,批量选出输入模型的三类feed数据,编码器的inputs和解码器的inputs,target_weights对encoder_inputs进行指示,为1表示已经预测的,为0表示PAD部分。
encoder_inputs, decoder_inputs, target_weights = model.get_batch(
train_set, bucket_id)
# 4.2 训练的Feed数据的构造
input_feed = {}
for l in xrange(encoder_size):
input_feed[self.encoder_inputs[l].name] = encoder_inputs[l]
for l in xrange(decoder_size):
input_feed[self.decoder_inputs[l].name] = decoder_inputs[l]
input_feed[self.target_weights[l].name] = target_weights[l]
# 4.3 由于目标词是由于Decoder左移一位了,所以需要再添加一位
last_target = self.decoder_inputs[decoder_size].name
input_feed[last_target] = np.zeros([self.batch_size], dtype=np.int32)
train_ops = [self.updates[bucket_id], # Update Op that does SGD.
self.gradient_norms[bucket_id], # Gradient norm.
self.losses[bucket_id]] # Loss for this batch.
outputs = session.run(train_ops, input_feed)
4Seq2Seq模型中存在的问题及相应解决的trick
问题1:tensorflow中的seq2seq例子为什么需要bucket?
问题描述:在处理序列问题时,每个batch中的句子的长度其实是不一的,通常做法是取batch中语句最长的length作为序列的固定的长度,不足的补PAD。如果batch里面存在一个非常长的句子,那么其他的句子的都需要按照这个作为输入序列的长度,训练模型时这将造成不必要的计算浪费。
加入bucket的trick:相当于对序列的长度做一个分段,切分成多个固定长度的输入序列,比如说小于100为一个bucket,大于100小于150为另一个bucket…。每一个bucket都是一个固定的computation graph。这样一来,对于模型输入序列的固定长度将不再单一,从一定程度上减少了计算资源的浪费。
问题2:Sampled Softmax
问题描述:Seq2Seq模型的代价函数的loss便是sampled_softmax_loss。为什么不是softmax_loss呢?我们都知道对于Seq2Seq模型来说,输入和输出序列的class便是词汇表的大小,而对于训练集来说,输入和输出的词汇表的大小是比较大的。为了减少计算每个词的softmax的时候的资源压力,通常会减少词汇表的大小,但是便会带来另外一个问题,由于词汇表的词量的减少,语句的Embeding的id表示时容易大频率的出现未登录词‘UNK’。于是,希望寻找到一个能使seq2seq模型使用较大词汇表,但又不怎么影响计算效率的解决办法。
trick:《On Using Very Large Target Vocabulary for Neural Machine Translation》论文中提出了计算词汇表的softmax的时候,并不采用全部的词汇表中的词,而是进行一定手段的sampled的采样,从而近似的表示词汇表的loss输出。sampled采样需要定义好候选分布Q。即按照什么分布去采样。
问题3:Encoder阶段的Beam Search
问题描述:我们知道在Seq2Seq模型的最终目的是希望生成的序列发生的概率最大,也就是生成序列的联合概率最大。在实际预测输出序列的每个token的时候,采用的都是最大化下一目标词(token)的概率,因为Decoder的当前时刻的输出是根据前一时刻的输出,上一个时刻的隐藏状态和语义向量Ci.通过依次求每个时刻的条件概率最大来近似获得生成序列的发生最大的概率,这种做法属于贪心思维的做法,获得是局部最优的生成序列。
trick:《Sequence-to-Sequence Learning as Beam-Search Optimization》论文中提出Beam-Search来优化上述的局部最优化问题。Beam-Search属全局解码算法,Encoder解码的目的是要得到生成序列的概率最大,可以把它看作是图上的一个最优路径问题:每一个时刻对应的节点大小为整个词汇表,路径长度为输出序列的长度。可以由动态规划的思想求得生成序列发生的最大概率。假设词汇表的大小为v,输出序列的长度为n.设t时刻各个节点(各个词w)对应的最优路径为dt=[d1,d2,…,dv].则下一个时刻(t+1)的各个节点对应的最优路径为dt加上t时刻的各个节点(各个词w)到(t+1)的各个节点(各个词w)的最短距离,算法的复杂度为o(nv^2).因为词汇表的大小v比较大,容易造成算法的复杂度比较大。为了降低算法的复杂度,采用Beam Search算法,每步t只保留K个最优解(之前是保留每个时刻的整个词汇表各个节点的最优解),算法复杂度为o(nKv).
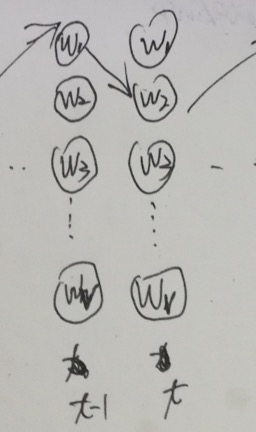
问题4:Exposure Bias
问题描述:Seq2Seq模型训练的过程中,编码部分的下一个时刻的输出,是需要根据上一个时刻的输出和上一个时刻的隐藏状态和语义变量Ci.此时上一个时刻的输出使用的是真实的token。而在验证Seq2Seq模型的时候,由于不知道上一个时刻的真实token,上一个时刻的输出使用的是上上个时刻的预测的输出token。这将引发Exposure Bias(曝光偏差问题)。
trick: 使用Beam Search的Encoder的方式也能一定程度上降低Exposure Bias问题,因为其考虑了全局解码概率,而不仅仅依赖与前一个词的输出,所以模型前一个预测错误而带来的误差传递的可能性就降低了。论文Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks中提出了DAD的方法,论文中提到Exposure Bias的主要问题是训练过程中模型不曾接触过自己预测的结果,在测试过程中一旦预测出现错误,那么模型将进入一个训练过程中从未见过的状态,从而导致误差传播。论文中提出了一个训练过程逐渐地迫使模型处理自己的错误,因为在测试过程中这是必须经历的。DAD提出了一种退火算法来解决这个问题,在训练过程中引入一个概率值参数εi ,每次以εi的概率选取真实的token作为输入, 1-εi的概率选取自己的prediction作为输入。逐渐降低εi,最终模型全都利用自己的prediction作为下一步的输入,和测试过程一致。
问题5:OOV和低频词
问题描述:OOV表示的是词汇表外的未登录词,低频词则是词汇表中的出现次数较低的词。在Decoder阶段时预测的词来自于词汇表,这就造成了未登录词难以生成,低频词也比较小的概率被预测生成。
trick:论文Abstractive Text Summarization using Seq2Seq RNNs and Beyond中使用Pointer-Generator机制来解决OOV和低频词问题。由于文本摘要的任务的特点,很多OOV 或者不常见的的词其实可以从输入序列中找到,因此一个很自然的想法就是去预测一个开关(switch)的概率P(si=1)=f(hi,yi-1,ci),如果开关打开了,就是正常地预测词表;如果开关关上了,就需要去原文中指向一个位置作为输出。
17年的论文Get To The Point: Summarization with Pointer-Generator Networks使用Pointer-Generator Networks)使用Pointer-Generator Networks解决OOV问题,pointer-generator network相当于在每次摘要生成过程中,都会把原文中的词汇动态地加入到词表中去。
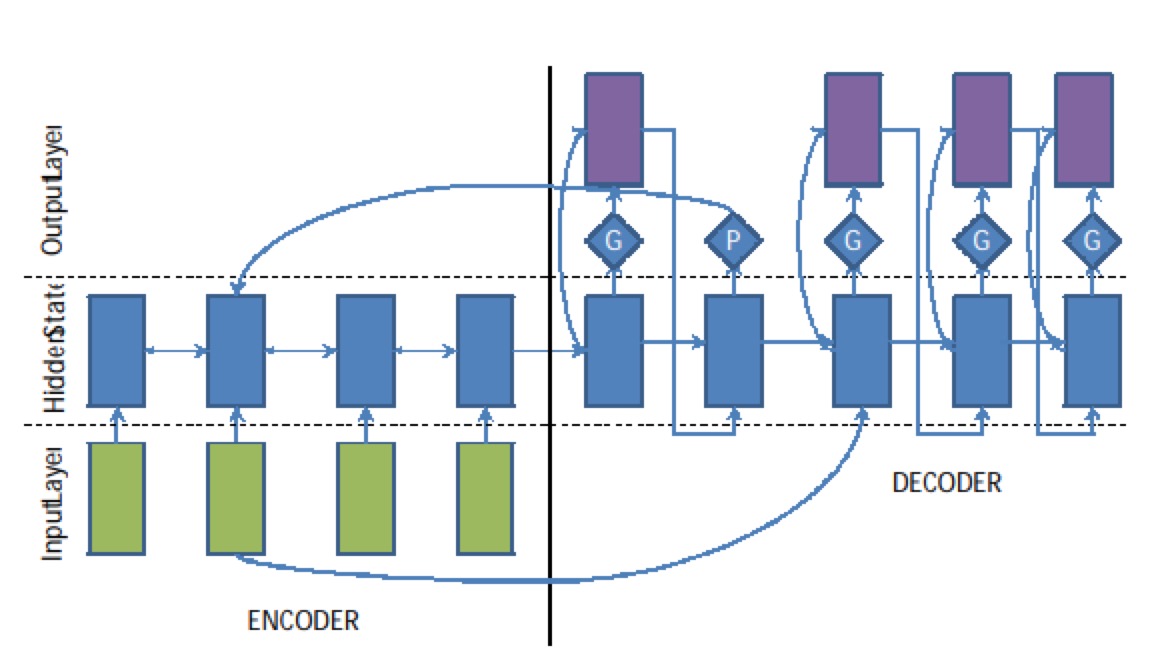
问题6:连续生成重复词的问题
问题描述:在Seq2Seq的解码阶段,生成序列是很可能会生成连续的重复词。
trick:论文Get To The Point: Summarization with Pointer-Generator Networks使用Pointer-Generator Networks)中使用Coverage mechanism来缓解重复词的问题,模型中维护一个Coverage向量,这个向量是过去所有预测步计算的attention分布的累加和,表示着该模型已经关注过原文的哪些词,并且让这个coverage向量影响当前步的attention计算。其中ci表示之前时刻的预测的attention分布和。
此外,该论文中添加了一个coverage loss用于惩罚对重复的attention。ai表示当前时刻的attention,ci表示之前时刻的预测计算的attention分布的累加和。

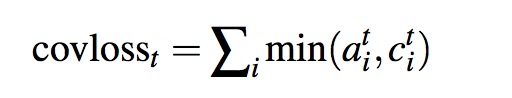
5参考链接
Text Summarization 综述
Google实现的Text_Sum
tensorflow学习笔记(十一):seq2seq Model相关接口介绍
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation