1前言
本篇博客主要详细介绍两种具有一定相似性的机器学习算法——感知机Perceptron和支持向量机SVM,该两种算法都是在特征空间中寻找划分平面从而对数据集进行划分的思想,但寻找划分平面的算法不同。划分平面的定义也有差距。本篇博客主要叙述思路为算法模型,代价函数,学习算法,最后的算法模型使用实例介绍。
这两种机器学习的算法的实例都是基于Titanic数据集,关于数据集的特征工程部分就不具体介绍,笔者在其他博文中已经详细描述了,此篇博客将直接使用已经经过特征工程处理后的数据集进行模型训练。
一般来说,对于一个机器学习算法的理解,主要是从三个方面入手理解,算法模型(假设函数),代价函数的定义,学习算法(求解算法模型中的参数的算法)。
2感知机
2.1感知机介绍
感知机是一个二类分类的线性分类模型,作为一个算法模型,它的输入是样本的特征向量,输出是样本的类别,分别为-1和1两个值。如果label是1,0的情况,可以对输出的-1,1进行相应的转换。
2.2感知机算法模型
了解感知机模型之前,先得知道什么是数据集的线性可分。简单的说,就是在特征空间(维度是由各个特征组成的空间)中,存在某个超平面S能够将数据集中的正例和负例完全正确的划分到超平面的两边。则称该数据集的可以进行线性划分。————此处的S是线性超平面。
用数学的解释来说就是,特征空间中的样本集将被超平面w*xi+b进行划分,当超平面>0,是属于yi为1的样本,当超平面<0,是属于yi为-1的样本。
于是可以定义出感知机的算法模型为如下: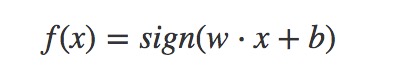
2.3代价函数
代价函数主要来自于算法模型预测样本时的预测值和样本真实值直接的差距,感知机的损失函数定义为样本集中误分类点到超平面的距离。这样定义的原因为如果定义为误分类点的个数时,使用梯度下降算法更新参数时,需要对各个参数求偏导,定义为个数时,不可导。所以转而将代价函数定义为为样本集中误分类点到超平面的距离。这里可以联想到Adaboost的加法模型的代价函数,代价函数是分类误差率,而后对其代价函数的值上限进行了转换为指数函数具体查看前篇博客。
2.3.1感知机的代价函数的由来
特征空间中样本实例到超平面wxi+b的距离为(其中||W||为w的L2范式,即w中各个元素的平方和再开方):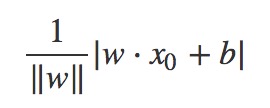
2.3.2误分类点(xi,yi)的特性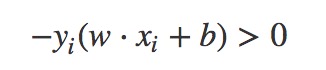
解释:假设特征空间中的样本点(xi,yi)是误分类点,则有wxi+b>0,yi=-1,或者w*xi+b<0,yi=1.所以总结出上面图中的特性。
可以推出该误分类点到超平面的距离为(注意|yi|=1,所以下面计算距离的公式有yi不影响最后的距离值):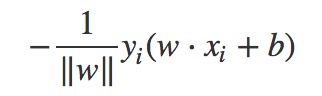
进而可以得出总的样本集合中所有的误分类点的总距离为(其中M属于总的样本集合中所有的误分类点集合):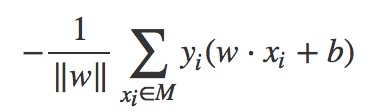
李航的<<统计学习方法>>中代价函数没有考虑1/||w||,从而将上式进行了化简: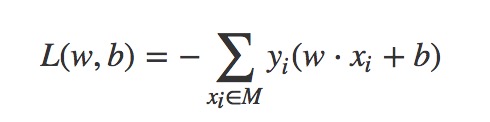
能这样化简的原因(个人理解):
在使用梯度下降更新参数w时,每一步迭代过程中1/||w||是相同的,都是大于0的正数。在每一步迭代更新参数过程中,由于1/||w||是相同的,所以可以通过比较-yi(wxi+b)来比较误分类点到超平面的距离,也就是说能通过误分类点的-yi(wxi+b)值评价代价的大小。
2.4学习算法
机器学习算法模型的学习算法的目的就是求解出模型中的参数w,b.感知机使用的是梯度下降算法来求解参数。通过极小化代价函数来求解出参数。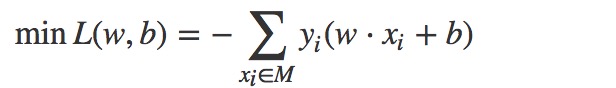
这里使用的是随机梯度下降算法,其中误分类集中的点可以通过误分类点的特性来判断。随机拿取出误分类点来更新参数。
具体梯度下降算法的每一步参数更新为如下: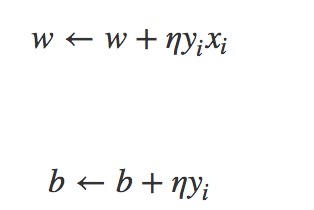
2.5学习算法的收敛性
需要证明的是,对于线性可分数据集感知机学习算法原始形式收敛,即经过有限次的梯度下降法的迭代可以得到一个将训练数据集完全正确的划分的超平面S。
证明的方法和重点,这里不具体证明。
1.实现需要定义出K的值,即假设已经计算好前k-1次的迭代,于是可以得出第K步迭代的相应公式。
2.抓住误分类点的特性yi(wxi+b)<0的,当得到超平面的时候,所有的点都是yi(wxi+b)>=0的存在。
2.6基于感知机的Titanic数据集预测实例
完整代码地址
数据集下载地址和特征工程处理链接前言中已经给出。
整个算法模型的代码实现步骤图(截取网上):
重点代码——模型训练代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37def train(self,train_X,train_y):
feature_size = train_X.shape[1]
sample_size = train_X.shape[0]
# 初始化w,b参数
self.w = np.zeros((feature_size,1))
self.b = 0
update_count = 0
correct_count = 0
while True:
if correct_count > self.nochange_count_limit:
break
# 随机选取一个误分类点
sample_select_index = random.randint(0,sample_size-1)
sample = train_X[[sample_select_index]]
sample_y = train_y[sample_select_index]
# 将labe分类为0,1转换为-1,1,其中0对应-1,1对应着1
y_i = -1
if sample_y == 1:
y_i = 1
# 计算该样本的distance距离yi(xi*w)+b
distance = - (np.dot(sample,self.w)[0][0] + self.b) * y_i
if distance >= 0:
# 挑选出误分类点,更新w,b
correct_count = 0;
sample = np.reshape(sample,(feature_size,1))
add_w = self.alpha * y_i * sample
self.w = self.w + add_w
self.b += (self.alpha * y_i)
update_count += 1
if update_count > self.updata_count_total:
break;
else:
correct_count = correct_count + 1

3支持向量机SVM
支持向量机也是在特征空间中寻找一个划分样本实例类别的超平面,这点和感知机相似,但是不同的是,支持向量机支持在特征空间中寻找出非线性的平面(非线性支持向量机).支持向量机寻找出的超平面唯一且最优,而感知机是根据误分类点定义出的代价函数求得的超平面不唯一,包含多个。
3.1支持向量机的类型介绍
支持向量机是一种二类分类模型,该算法的基本模型是在特征空间中寻找出一个最优的分隔超平面,使得样本集实例按照类别分开。由于数据集是有线性可分和不可分性质的,所以可将寻找最优分割平面的支持向量机算法分为3种类型,当数据集线性可分(能找到超平面将数据集完全按类别划分开)时,有线性可分支持向量机。当数据集近似线性可分(能找到超平面将大部分数据集按类别划分开),有线性支持向量机。当数据集线性不可分的时候,有非线性支持向量机。
那么,如何定义划分的最优超平面?这个疑问将在后续的过程中一一解开。
3.2线性可分支持向量机
给出一个在特征空间(二维)中的样本数据集的示例,如下图: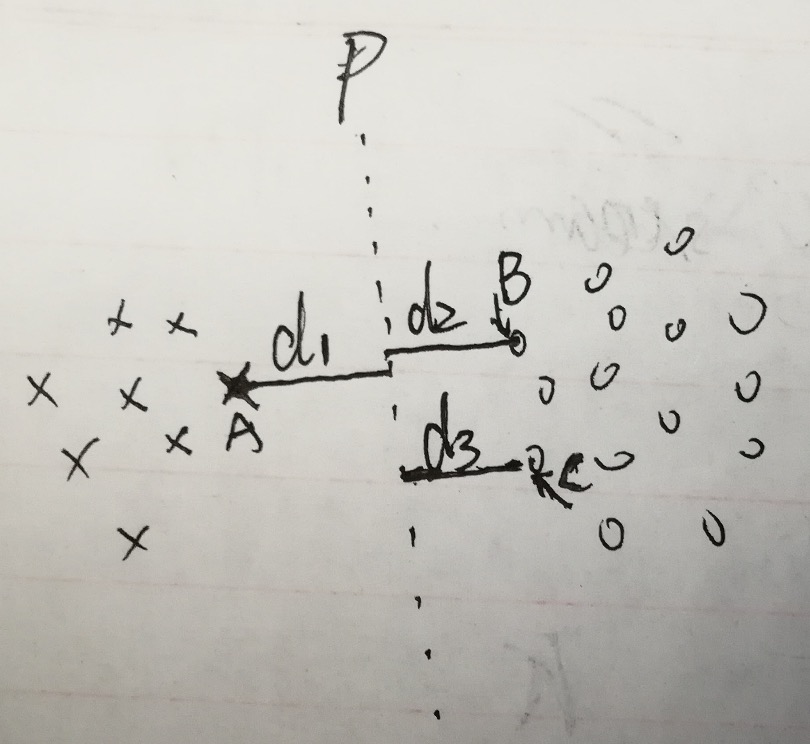
说明,图中p是划分数据集的一个超平面,d2=d3,d3不一定等于d1.A表示X类别实例在特征空间中到超平面P距离最近的一个样本实例点。同理B和C表示O类别在特征空间中到超平面P距离最近的一个样本实例.
对于线性可分支持向量机来说,图中数据集是线性可分的,p是划分的一个超平面,但不一定是最优的,这样的超平面通过迭代算法可以查找到很多个(感知机模型),感知机模型这样找出的超平面泛化能力不强,如果能找到一个最优超平面将提供模型的泛化能力。线性可划分支持向量机的做法是通过移动超平面P使得d3=d1,此时的P将是最优超平面。那么特征空间中的样本点A、B、C将会是对最优超平面起决定性作用,这些样本实例点称为支持向量。
—》》那么具体的如何寻找这个最优超平面呢,还是需要通过优化算法模型的代价函数来求解。
3.2.1代价函数的由来
首先,特征空间中样本实例到超平面wxi+b的距离为如下图:(其中||W||为w的L2范式,即w中各个元素的平方和再开方):
然后,要在众多可以正确划分数据集实例类别的超平面之中找到一个最优超平面P,需要先找到上面所说的支持向量A、B、C。寻找支持向量的数学表达为: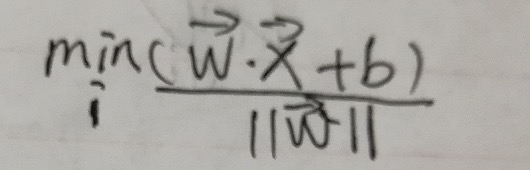
其次,上面我们已经表明过最优超平面是使得d3=d1,寻找支持向量的过程中是找到离超平面最近的点,假设是A样本点,则此时最小的距离是d1,要使得d3=d1,则需要把d1极大化,此时便能求出参数W,b。数学公式为: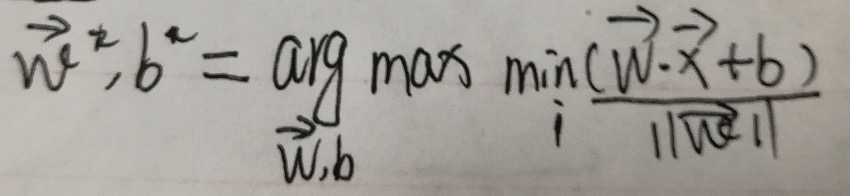
问题来了,是需要在众多可以正确划分数据集实例类别的超平面之中找到一个最优超平面P,怎么获取和保证是可以正确划分数据集实例类别的超平面呢???怎么保证寻找的支持向量的样本点到超平面的距离是所有样本中的最小呢?
感知机模型中判断是否是误分类点是通过yi(wxi+b)<0来判断的。正确分类的样本点满足yi(wxi+b)>=0.
为了解决上述问题,需要满足的数学公式为:
最后,在满足上面问题的条件后,需要做的就是移动超平面使的距离最小的支持向量样本点到超平面P’的距离d1最大。
最后的数学公式为: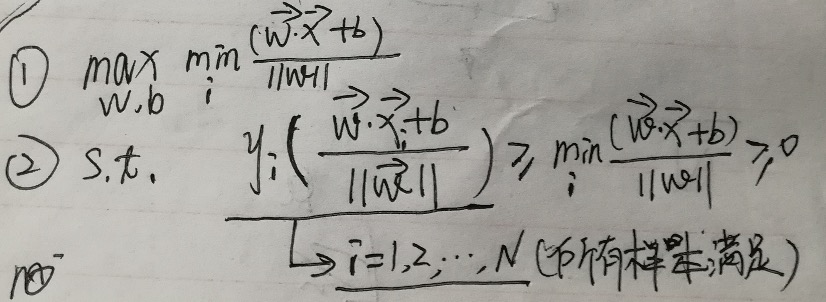
最后的数学公式也就是线性可分支持向量机的代价函数。说明部分,上面的代价函数的推导过程是根据最初的最优超平面的定义来的。
接下来就是对代价函数(上面的数学公式进行化简):
最后的再进行优化变换为: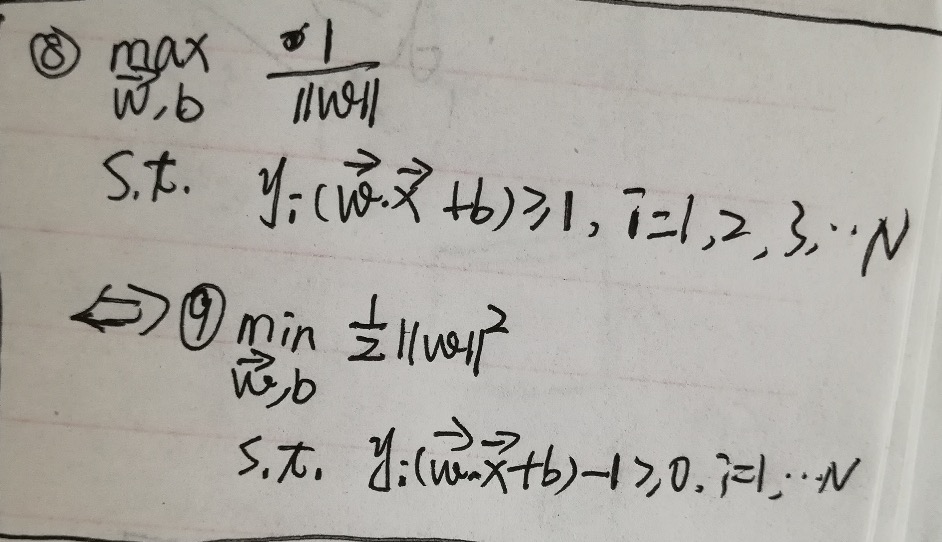
说明
第7步可能会有疑问——为什么函数距离可以取1,第5步中的w,b是经过伸缩变化后的不等式和等式两边进行约分的,化简后的第8步中的w,b是第5步中伸缩变化后的w,b.也就是经过了我们的第6步变化。
第9步也可能会有疑问,为什么优化变化成二次的||W||,主要是为了构造成一个凸二次规划问题。更容易求解出极值,从而求解出参数w,b.
3.2.2学习算法
主要是求解代价函数中的参数w,b的过程。最终我们的代价函数经过一些数学变化成凸二次规划问题。φ(xi)为xi的一个映射函数。此时φ(xi)=xi.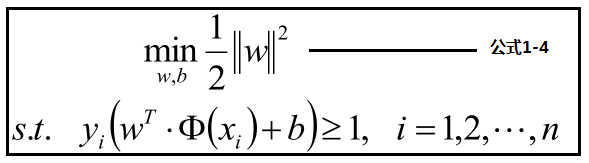
上面这个优化问题中,自变量是w,而目标函数是w的二次函数,共有N(样本总数量)个约束条件,每个约束条件都是线性函数,并且它的可行域是一个凸集,所以该优化问题是一个凸二次规划问题。
为了求解上面的凸二次规划问题,需要使用到高等数学中的拉格朗日函数和KTT条件优化公式:
3.2.2.1高等数学知识——拉格朗日函数及对偶性
为了把凸优化的问题变得易于处理,需要把目标函数和约束全部融入一个新的函数,即拉格朗日函数。再通过这个函数来寻找最优点。
1.一般的有(包含目标函数和约束条件(此时的约束为多个等式约束条件)):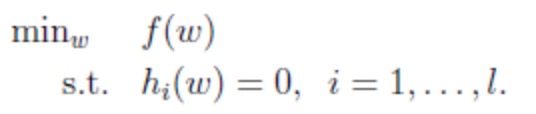
转换为一个自变量为W和βi的拉格朗日函数L,其中βi为拉格朗日算子: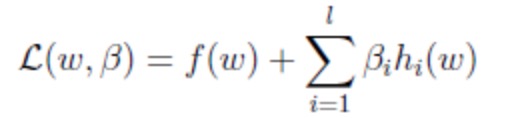
然后分别对w和βi求偏导,使得偏导数等于0,然后解出w和βi。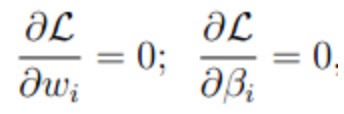
为什么可以求出极值可参考图: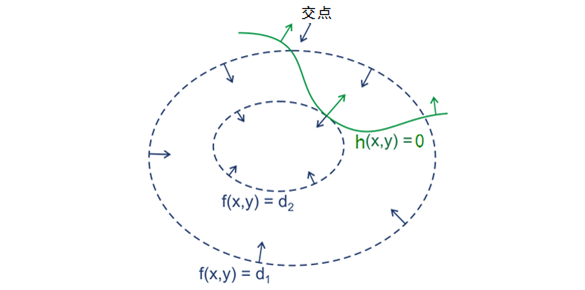
2.其次还有(包含目标函数和约束条件(此时的约束为不等式约束和等式约束)):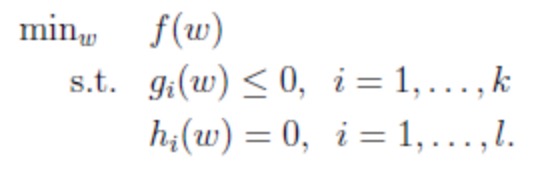
同样可以转换为一个函数表达式,但函数最终的最优值需要满足如下KTT条件: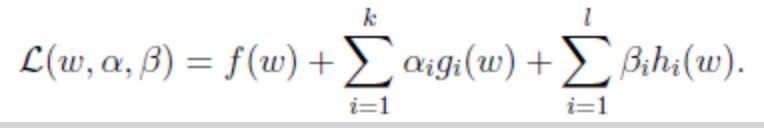
KTT条件如下:
解释获取极值图:
将带约束的原函数进行对偶性转换过程如下:
3.2.2.2代价函数的拉格朗日对偶转换及参数求解
在理解上述凸优化数学知识后,便可对SVM的数学代价函数进行参数求解。还有对该部分数学不理解的可以查看下面的参考链接。
满足不等式的拉格朗日函数为: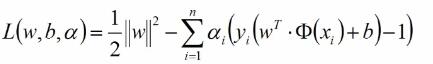
将带约束的原函数进行对偶性转换:
原始问题: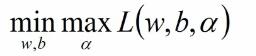
对偶问题:
接下来就是对对偶问题的求解:主要有两步第一步先求L(W,b,α)对w,b的极小,第二步再求α的极大值。
第一步L(W,b,α)对w,b的极小将L对w,b求偏导并令其等于0得,称为结果1:
第二步再求α的极大值,将结果1代入L(W,b,α)中: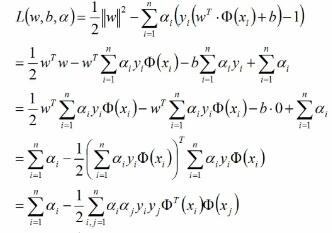
第二步的结果为(在要求的式子上取反就相当于求极小了):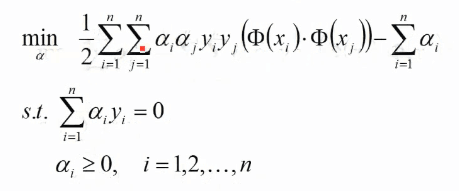
此时便可以用只含有等式的拉格朗日函数求解出最优值α,将α的值结合KTT条件,求出w,b:
3.3线性支持向量机
如果数据集本身线性不可分(但近似线性可分?)这个时候应该怎么解决分类问题呢?————线性支持向量机
3.3.1代价函数的由来
我们知道线性可分支持向量机的凸优化问题为:
线性支持向量机针对的是数据集不可划分问题(近似可划分)。这里的显示不可划分是指数据集中存在某些样本点不能满足线性可分支持向量机的约束条件: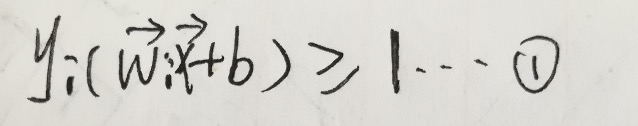
为了使造成数据集不可划分的样本点也满足约束条件(这样的目的是让整个数据集又重新可以线性划分),给每个样本点(xi,yi)引入一个松弛变量ξi>=0.如此一来,可以容忍部分样本点的函数间隔是负数即错误分类了,或者部分样本点能落在最大间隔区间。
由于对每个样本都在函数间隔上添加了松弛变量ξi,需要支付一个代价ξi。线性支持向量机目标函数就变为: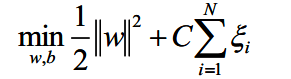
最终加上约束条件,最终的代价函数为: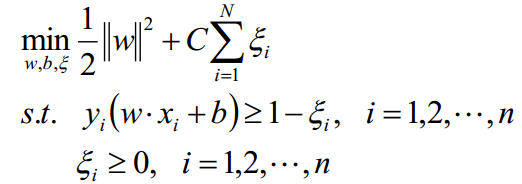
3.3.2学习算法
线性支持向量机的代价函数和线性可分支持向量机的代价函数都是凸二次规划问题,都需要使用拉格朗日函数及其对偶函数来求解参数。先将目标原函数和约束条件转换为拉格朗日函数(其中α和μ大于等于0):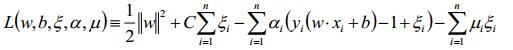
此处根据拉格朗日函数的对偶性转换(拉格朗日对偶函数对拉格朗日乘子极大值和原目标函数的关系,线性可分支持向量机那节中有说明)有:
步骤1:求解对参数w,b,ξ的极小,求解的最后值称为结果2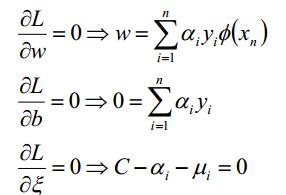
步骤2:将结果2代入拉格朗日函数,求解代入后的值对拉格朗日乘子的极大。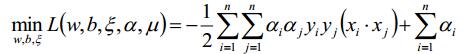
对上面这个式子求极大。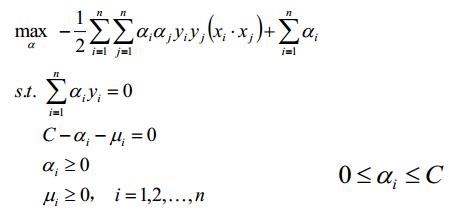
再次进行化简(对上式子的极大就是求该式子的负数的极小):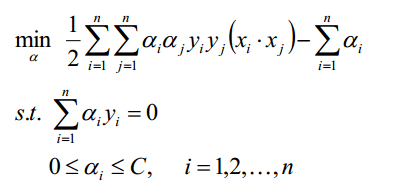
步骤3,此时可以理解为只有等式约束的优化问题,对变量求偏导等于0,再验证值是否满足C>=α>=0,此处使用SMO算法求解,最后将α值代入结果2中: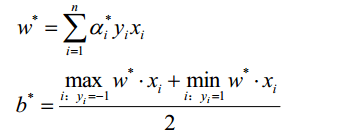
3.4非线性支持向量机
前面叙述的数据集都是在当前维度的特征空间中,可以进行线性划分和近似线性划分。但是如果当前维度的特征空间无法近似划分,就是一个完全不可划分的数据集时,这时候会使用到核函数将当前维度的特征空间映射到高维空间,让数据集在高维空间中线性可分。
3.4.1核函数
1.此处具体分析居然核函数是怎样发挥它的作用呢?
我们的最终目标是希望数据集线性可分,这样才能寻找出一个可划分的最优超平面。我们都知道,样本点数据在低维度特征空间中不可划分,但是如果将样本数据点映射到高维特征空间中,数据集将可进行线性划分。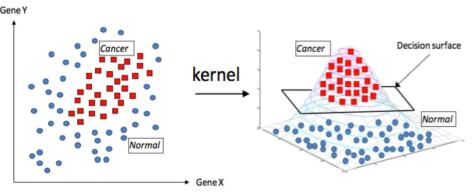
2.映射函数上式是线性可分支持向量机的凸优化问题的式子。其中有个φ(xi),它是xi的一个映射函数。当数据集在当前维度的特征空间中线性可分时候,φ(xi)=xi。如果不可划分时候,此时φ(xi)将xi样本点映射到更高的特征空间中让数据集线性可分。比如说xi=(1,2),是一个二维向量。经过φ(xi)=(1,2,4),映射到三维向量了。
3.核函数的映射方式
核函数并不是直接定义φ(xi)来将当前维度的特征空间里的样本点映射到高维度特征空间。而是采用间接的方式映射。
为什么采用间接的方式映射??
我们的凸二次规划原问题的对偶问题为:
1.从上面式子来看,每次我们求极值的时候都需要计算(φ(xi)·φ(xj))的,为了简化每次将xi映射到φ(xi再运算φ(xi)·φ(xj)的点乘以,我们可以直接定义K(xi,xj)=φ(xi)·φ(xj)的表达式,从而不定义φ(xi),但是这之间是隐含着一个φ(xi)映射的过程的。其中K(xi,xj)就是我们的核函数。这样一来便简化了计算过程。
2.映射函数的存在是为了便于我们了解低维度空间到高维度空间的映射的理解,其实可以通过函数K(xi,xj)反推出映射函数φ(xi)。只是对于凸优化求极值的过程中只关注核函数的表达式。
3.注意,核函数间接是可以将低维特征空间映射到无穷维特征空间,具体证明需要使用到泰勒展开式。
4.常用的核函数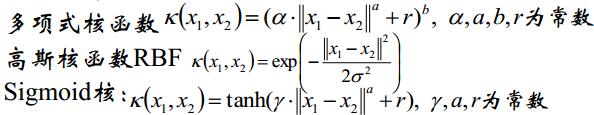
3.4.2学习过程
求解原问题的对偶问题时,我们需要选取核函数,根据情况来选取核函数,当我们不知道先验知识的时候,优先选用高斯核函数。选取好后,我们便可以将(xi,xj)代入到核函数,从而求解出凸优化的极值点。
4总结
1.感知机是基于误分类点驱动来更新参数w,b.如何判断是分类点是根据yi(w*xi+b)<0的。代价函数为误分类点到超平面的距离最小。这样只要能正确划分出正负实例代价函数就能达到最小。所以感知机模型求得的超平面有多个。
2.对于线性可分支持向量机模型的求解,首先定义好最优超平面,什么是最优。然后在可正确划分数据集类别的超平面中寻找支持向量(距离超平面最近的点),然后最大化超平面到支持向量间的距离(几何距离)。
3.线性可分支持向量机的代价函数为凸二次规划问题,对于约束为等式的优化问题,可以使用拉格朗日函数求极值来得到参数。对于约束含有不等式的优化问题,这时不能直接采用求极值的方法,应该先转换为拉格朗日函数,再获取该拉格朗日函数的对偶函数,求对偶函数的最大值,最终原始问题为极小极大问题。紧接着求原始问题的对偶问题在满足KTT条件下转换为极大极小问题。在进行求参化简。
4.核函数是间接进行将低维特征空间的样本集映射到高维特征空间去的。
5参考链接
用Python实现感知器模型
感知机模型
拉格朗日对偶
深入理解拉格朗日乘子法(Lagrange Multiplier) 和KKT条件
SMO算法剖析
数据挖掘(机器学习)面试–SVM面试常考问题