1前言
本篇博客主要记录的是XGBoost在构建决策树结构时,知道如何评定划分点的好坏的情况下,如何遍历查找出该树结构的切分点。前篇博客决策树相关算法——XGBoost原理分析及实例实现(一)介绍的是贪心查找算法,逐步遍历特征和特征取值,比较切分前后的平方误差的大小,获得最佳切分点。本篇主要介绍的是近视查找算法和稀疏感知的划分查找。
2要说的话
我们知道决策树中的ID3算法和C4.5或者是CART分类回归树的构造过程中都是有一个切分评价标准,ID3进行特征选择的是信息增益,C4.5是信息增益率。而CART分类树构造的切分点是根据选择的特征和特征值的Gini系数进行对比。CART回归树是根据切分点后的平方误差进行评价的。我们的XGBoost的决策树构建过程中切分点的选择是根据代价函数(代价函数可以是任意的一般函数)的化简值——如下图所示。具体化简过程参照上篇博客。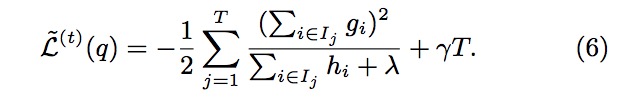
3近似查找算法(Approximate Algorithm)
原因: 完全贪心算法,贪婪的遍历所有的切分点,当所有的数据点不能全部加载到内存时,算法就会变的低效。同时在XGBoost分布式学习时也会遇到这样的问题。所以此时需要一些近似算法来获取切分点列表。
XGBoost中的近似方法框架
算法讲解: 前面一个for循环做的工作是,对特征K根据该特征分布的分位数找到切割点的候选集合Sk={sk1,sk2,...,skl},这样做的目的是提取出部分的切分点不用遍历所有的切分点。其中获取某个特征K的候选切割点的方式叫proposal.主要有两种proposal方式:global proposal和local proposal.
第二个for循环的工作是,将每个特征的取值映射到由这些该特征对应的候选点集划分的分桶(buckets)区间{skv≥xjk>skv−1}中,对每个桶(区间)内的样本统计值G、H进行累加统计,最后在这些累计的统计量上寻找最佳分裂点。这样做的主要目的是获取每个特征的候选分割点的G和H量。
存在的疑惑——后面会讲解:
问题1.如何根据特征分布的分位数挑选出候选点集??
问题2.global proposal和local proposal有什么不同??
3.1分位点(quantile)介绍
举例子说明,一般来说对于一个数据列表有:
ϕ−quantile表示rank=⌊ϕ−quantile×N⌋的元素
我们需要取出0.25-quantile(0.25分位点的数),即取出rank为0.25*N的数。
3.2加权分位点(Weighted quantile)介绍
举例子说明,一般来说对于一个数据列表有,取元素的方法为,指定rank(大于0小于1)即可,0.5分位点的元素为3:
3.3分位数缩略图(Quantile Sketch)
原因: 当一个序列无法全部加载到内存时,常常采用分位数缩略图近似的计算分位点来近似获取特定的查询。
方式:使用随机映射(Random projections)将数据流投射在一个小的存储空间内作为整个数据流的概要,这个小空间存储的概要数据称为略图,可用于近似回答特定的查询。需要保留原序列中的最小值和最大值。
3.4近似算法中的分位数缩略图(Weighted Quantile Sketch)
此部分便是讲述疑惑中的问题1:如何根据特征分布的分位数挑选出候选点集???
通常,一个特征的百分位数可以被用来让候选在数据上进行均匀地分布。我们用一个multi-set: Dk=(x1k,h1),(x2k,h2),…(xnk,hn),来表示每个训练实例的第k个特征值以及它的二阶梯度值统计。其中hi表示i个实例的第k个特征值对应的二阶梯度值统计,可看作i个实例的第k个特征值的权重。至于为什么可以看作是权重作为疑惑问题3后面会提到。
如下示例有: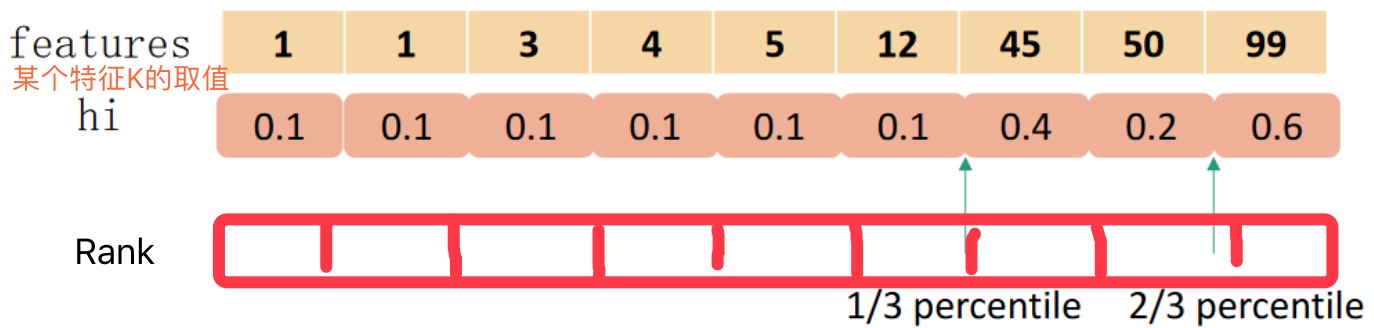
一般来说对于加权分位数缩略图的取值是根据Rank的值进行的,Rank计算公式为: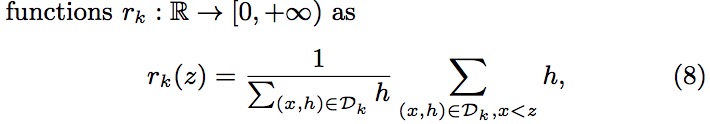
该Rank函数,输入为某个特征值z,计算的是该特征所有可取值中小于z的特征值的总权重占总的所有可取值的总权重和的比例,输出为一个比例值。于是我们就能用下面这个不等式来寻找候选分离点{sk1,sk2,sk3,⋅,⋅,skl}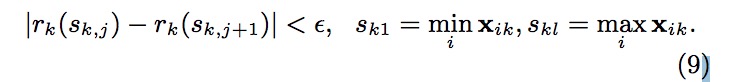
其中sk1是特征k的取值中最小的值xik,其中skl是特征k的取值中最大的值xik,这是分位数缩略图的要求需要保留原序列中的最小值和最大值。ϵ是一个近似比例,或者说是扫描步幅。可以理解为在特征K的取值范围上,按照步幅ϵ挑选出特征K的取值候选点,组成候选点集。起初是从sk1起,每次增加ϵ∗(skl−sk1)作为候选点,加入到候选集中。如此计算的话,这意味着大约是 1/ϵ个候选点。
此时特征k的取值中最小的值xik和特征k的取值中最大的值xik来自的数据集Dk,对于Dk的数据集有两种定义,一种是一开始选好,然后每次树切分都不变,也就是说是在总体样本里选最大值skl和最小值sk1,这就是我们之前定义的global proposal。另外一种是树每次确定好切分点的分割后样本也需要进行分割,最大值skl和最小值sk1来自子树的样本集Dk,这就是local proposal。
疑惑问题3,对于特征K的取值为什么权权可以表示为hi为二阶梯度的值?
首先,将代价函数公式进行转换:
最后的代价函数就是一个加权平方误差,权值为hi,labels为-gi/hi.所以可以将特征K的取值的权重看成对应的hi。
分布式加权分位数缩略图:对于需要并行的获取候选集切割点,需要使用分布式加权分位数缩略图,必须包含两个操作m合并erge和修剪prune。分布式加权分位数缩略图具体如何操作需要查看论文XGBoost: A Scalable Tree Boosting System附录1.
4稀疏感知的划分查找算法(Sparsity-aware Split Finding)
数据集稀疏的原因:1.样本中的部分数据缺失。2.统计中过多的 zero entries。3.特征工程中的one-hot encoding。
于是XGBoost中提出了稀疏感知的划分查找算法,如下:
如下为带缺省方向的树结构。当在split时相应的feature值缺失时,一个样本可以被归类到缺省方向上。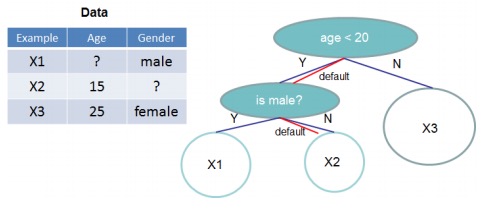
大体思想流程是:在每个树节点上增加一个缺省的方向(default direction),如上图所示,当稀疏矩阵x中的某个特征值缺失时,该样本实例被归类到缺省方向上。默认的缺省方向有两种,一个是左分支和右分支。XGBoost指定的默认缺省方向是从数据中学习到的,并不是随机指定的。
稀疏感知的划分查找算法的理解:至于缺省值的实例分到哪个分支方向,如何学习的问题,稀疏感知的划分查找算法计算切分后的评判标准(公式六)时只关注没有缺失的条目Ik.然后再通过将实例以枚举的方式,枚举项为默认分到左分支和默认分到右分支,计算切分前后相差最大的Score,然后将缺失值的实例分到该分支上。
5总结
1.传统的GBDT是以CART作为基分类器,XGBoost支持其他分类器。
2.XGBoost是带着代价函数的正则化进行切分查找,易于防止过拟合。
3.XGBoost的决策树的生成过程是先确定好每个叶子的权重,再寻找切割点来构造树结构。
6参考链接
xgboost之分位点算法
决策树相关算法——XGBoost原理分析及实例实现(一)
XGBoost: A Scalable Tree Boosting System